Calculating the k-core of a graph by iteratively pruning vertices is easy enough. However, for my application, I'd like to be able to add vertices to the starting graph and get the updated core without having to recompute the entire k-core from scratch. Is there a reliable algorithm that can take advantage of the work done on previous iterations?
For the curious, the k-core is being used as a preprocessing stage in a clique finding algorithm. Any cliques of size 5 are guaranteed to be part of the 4-core of a graph. In my data set, the 4-core is much smaller than the whole graph so brute-forcing it from there might be tractable. Incrementally adding vertices lets the algorithm work with as small of a data set as possible. My set of vertices is infinite and ordered (prime numbers), but I only care about the lowest numbered clique.
Edit:
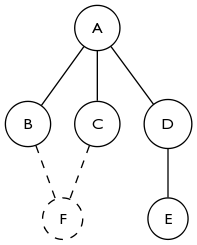
Thinking about it some more based on akappa's answer, detecting the creation of a loop is indeed critical. In the graph below, the 2-core is empty before adding F. Adding F does not change the degree of A but it still adds A to the 2-core. It's easy to extend this to see how closing a loop of any size would cause all of the vertices to simultaneously join the 2-core.
Adding a vertex can have an effect on the coreness of vertices an arbitrary distance away, but perhaps this is focusing too much on worst-case behavior.
-
It seems to me that an algorithm for an incremental k-core computation based on local exploration of the graph, instead of a "global" iterative pruning, would need an incremental loop detection in order to see which edges could contribute to enter a vertex in the k-core, which is an hard problem.
I think that the best you can do is to recompute the k-core algorithm at each pass, just removing from the graph the vertices that already are in the k-core and initializing, in the map vertex -> "k-core adjacent vertices" the number of adjacent vertices that already are in the k-core.
From akappa -
Quick idea: You could save the history in a list L, i.e., save the order in which the nodes where removed. Whenever you add a new node v, start at the first node w in L which is adjacent to v. Then just go through the remaining nodes in L from w on in linear order. (And test the node v as well and possibly add it to L.)
From jacob
0 comments:
Post a Comment